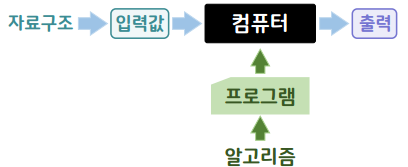
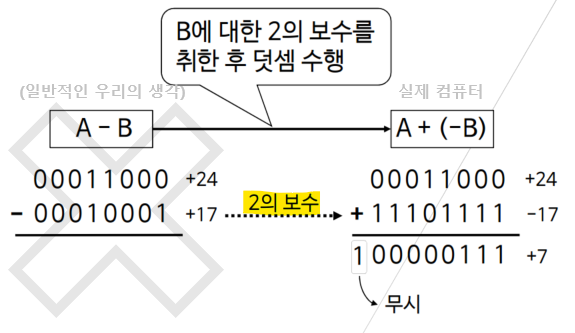
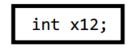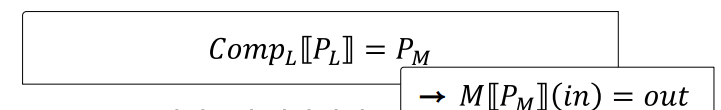특정 타입의 데이터를 가지고 연산을 하면 그 연산의 결과도 항상 해당 데이터 집합 안에 존재해야 됨!
나머지 연산: mod, % (예: 7 mod 3 = 1)
비트 연산: ^, &, | 등
관계 연산: <, >, <=, >=, == != 등 → 연산의 결과 값은 논리형
✅ 실수형: 실수 데이터를 다루는 타입
🔸데이터 집합
-100.05, -8.7, 0.0, 1.234, 256.3500187 등
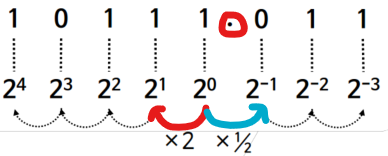
전체 실수 중 사용 비트의 크기에 따라 일부 범위의 실수만 표현 가능
일반적으로 부동소수점 수(floating-point number) 로 표현
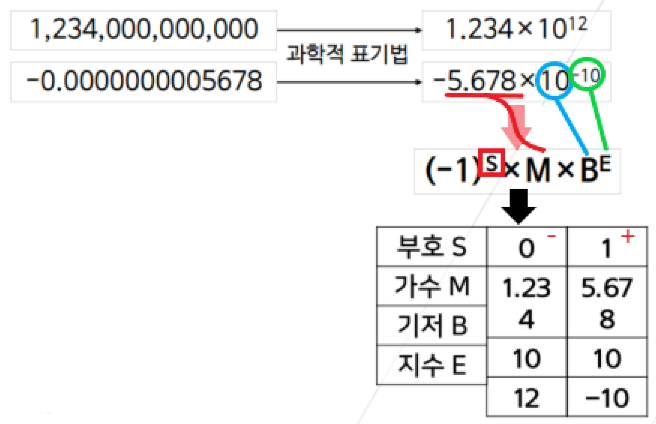
📌 부동소수점 수
출처: 방송통신대학교
부호: 양수 = 0, 음수 = 1
지수부: 지수 + bias
bias는 지수부의 크기에 따라 결정됨
(2^m-1)-1
가수부: 소수점 이하 부분만 표현
가수부는 1.xxxx 형태를 갖도록 정규화를 거침
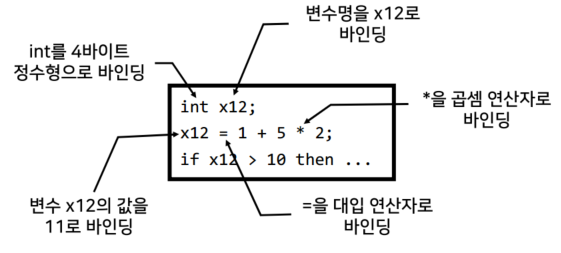
💡정수 5 vs 실수 5.0
short a = 5; //0 0000000000000101 float b = 5.0; //0 101 0100000000000000000
🔸연산 집합
사칙연산: 덧셈, 뺄셈, 곱셈, 나눗셈 → 연산 결과 값도 동일한 실수형 (예: 1.5 + 2.5 = 4.0)
float의 경우, 5E37*10.0 == 최대값 초과 → 무한대 inf
관계 연산: <, >, <=, >=, ==, != 등 → 연산 결과 값은 논리형
✅ 문자형: 하나의 문자 데이터를 다루는 타입 ('A', 'a'...)
🔸데이터 집합
ASCII: 특수기호, 구두점, 숫자, 영어 대소문자 등 128개의 문자로 구성
C, C++: char == 8비트
유니코드: 전 세계의 다양한 문자 표현 가능
Java: char == 16비트
🔸연산 집합
관계 연산: 연산의 결과 값은 논리형
'A' < 'B' == true
C, C++는 char 타입을 8비트 정수형으로 간주 → 사칙연산, 비트연산 등 가능
'A' + 32 == 65+32 → 97 == 'a'
'a' - 32 == 97-32 → 65 == 'A'
✅ 논리형: 참과 거짓의 논리 데이터를 다루는 타입
🔸데이터 집합
true(참), false(거짓)
C: _Bool = {0, 1}
C++: bool = {true, false}
Java: boolean = {true, false}
🔸연산 집합
논리곱(and), 논리합(or), 논리부정(not) 등
연산 결과 값도 동일한 논리형 → ture && false == false
✅ 열거형: 순서 관계가 있는 이름들을 데이터로 다루는 타입
🔸데이터 집합
사용자가 직접 지정한 이름들
각 이름은 0이상의 정수와 대응 → 순서 관계 성립
예) C, C++ enum 타입
/*
열두 달의 이름
개발자 입장에서는 이름을 사용했지만 컴퓨터 내부에서는 나열된 순서대로 이름마다 숫자를 대응
enum Year {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11};
*/
enum Year {Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec};
//각 이름에 대응되는 정수도 사용자가 지정 가능
enum Year {Jan=1, Feb, Mar, Apr=10, May=15, Jun=1, Jul, Aug, Sep, Oct, Nov, Dec};
🔸연산 집합
관계 연산: 연산 결과 값은 논리형
C: 대응되는 정수 값에 대한 사칙연산도 가능
#include <stdio.h>
int main()
{
enum Year {Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec};
enum Year Go;
for(Go=Jan; Go<=Dec; Go++)
printf("%d\n", Go); // 출력: 0 1 2 3 4 5 6 7 8 9 10 11
return 0;
}